
Интересны кое-какие результаты.
AMD выпустила серию полностью открытых больших языковых моделей (LLM) с миллиардом параметров под названием AMD OLMo. Модели, обученные на графических процессорах AMD Instinct MI250, предназначены для широкого спектра применений и обладают развитыми способностями к рассуждениям, выполнению инструкций и ведению диалога.
Открытый исходный код моделей позволит AMD укрепить свои позиции в сфере ИИ и предоставит клиентам (и всем остальным) возможность использовать их с оборудованием AMD. Неограниченный доступ к данным, методам обучения и коду позволит разработчикам не только воспроизводить модели, но и развивать их. Помимо развёртывания в дата-центрах, модели OLMo можно запускать локально на ПК AMD Ryzen AI с нейронными процессорами (NPU), что открывает возможности для использования ИИ на персональных устройствах. Модели AMD OLMo были обучены на массиве данных объёмом 1,3 триллиона токенов на 16 узлах, каждый из которых оснащён четырьмя графическими процессорами AMD Instinct MI250 (всего 64 процессора). Процесс обучения проходил в три этапа.
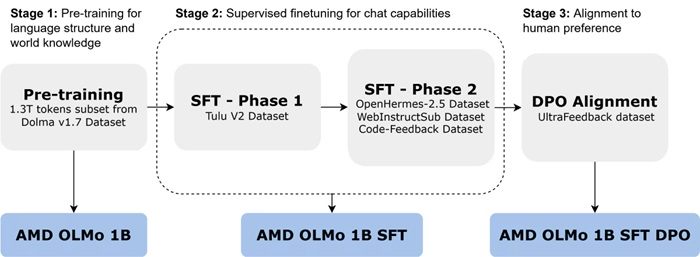
На первом этапе базовая модель AMD OLMo 1B была предварительно обучена на части набора данных Dolma v1.7. Эта трансформерная модель, работающая только в режиме декодера, ориентирована на предсказание следующего токена для усвоения языковых шаблонов и общих знаний.
Вторая версия, AMD OLMo 1B SFT, прошла дополнительное обучение на наборах данных Tulu V2 (первая фаза), OpenHermes-2.5, WebInstructSub и Code-Feedback (вторая фаза). Это позволило улучшить выполнение инструкций и повысить эффективность в задачах, связанных с наукой, программированием и математикой.
Наконец, модель AMD OLMo 1B SFT была адаптирована к человеческим предпочтениям с помощью метода прямой оптимизации предпочтений (DPO) на наборе данных UltraFeedback. В результате получена финальная версия AMD OLMo 1B SFT DPO, которая приоритизирует вывод, соответствующий типичной обратной связи от людей.
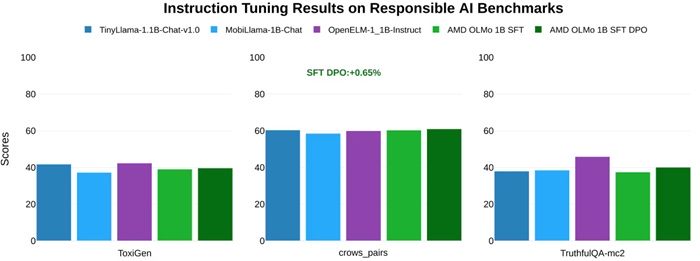
Тестирование AMD показало, что модели OLMo превосходят аналогичные открытые модели, такие как TinyLlama-1.1B, MobiLlama-1B и OpenELM-1_1B, в стандартных бенчмарках на общие способности к рассуждению и многозадачность. Двухфазная модель SFT продемонстрировала значительное повышение точности: результаты в MMLU выросли на 5,09%, а в GSM8k — на 15,32%. Финальная модель AMD OLMo 1B SFT DPO превзошла другие открытые чат-модели в среднем на 2,60% по всем бенчмаркам.
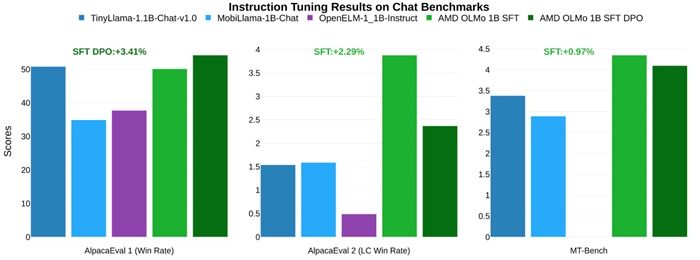
В тестах на способность выполнять инструкции в чатах, модели AMD OLMo 1B SFT и SFT DPO опередили ближайшего конкурента в AlpacaEval 2 Win Rate на 3,41% и в AlpacaEval 2 LC Win Rate на 2,29%. В тесте MT-Bench, оценивающем многоэтапные диалоги, модель SFT DPO показала прирост производительности на 0,97% по сравнению с ближайшим конкурентом.


